**Assignment 4 : Point Cloud Classification/Segmentation**
**Author:** *Rishikesh Jadhav (119256534)*
Classification Model
================
Visualization of Random test point clouds and predicted classes respectively.
------------------------
**Test Accuracy of best model(Trained for 125 epochs) : 0.9779**
| Point Clouds | Predicted Class | Ground Truth Class |
|-------------|-----------------|---------------------|
|  | chair | chair |
|  | vase | vase |
|  | lamp | lamp |
|  | chair | chair |
|  | lamp | lamp |
Visualization of Failed cases for each class
------------------------
| Point Clouds | Predicted Class | Ground Truth Class |
|-------------|-----------------|---------------------|
|  | chair | vase |
|  | vase | lamp |
|  | lamp | vase |
Interpretation
------------------------
**Analysis:**
In general, the classification model demonstrates strong performance across a variety of scenarios, with a few exceptions in rare and ambiguous situations. Notably, instances arise where the model struggles to distinguish between objects with similar but distinct characteristics. For example, it may misclassify a vase as having lamp-like features or perceive a lamp or vase as resembling a chair due to ambiguous boundaries. These challenges may stem from the model's emphasis on learning spatial relationships rather than delving into the semantic nuances of each object's characteristics. Consequently, the model may encounter confusion in these ambiguous cases, leading to misclassifications.
Segmentation Model
================
Visualization of Random test segmentation mask ground truths, predicted classes and accuracies respectively.
------------------------
**Test Accuracy of best model(Trained for 80 epochs) : 0.8884**
| Segmentation Ground Truths | Prediction | Accuracy |
|-------------|-----------------|---------------------|
|  |  | 0.9816 |
|  | 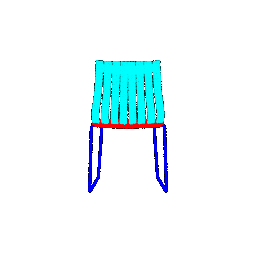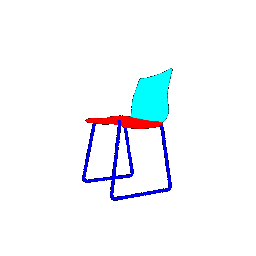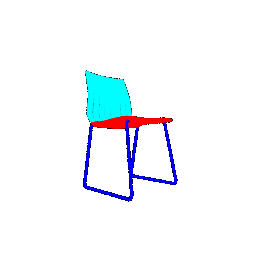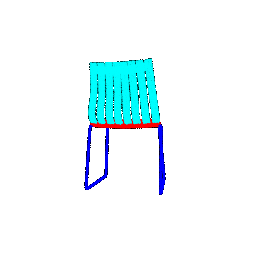 | 0.9771 |
|  |  | 0.9761 |
|  |  | 0.9740 |
|  |  | 0.9708 |
Visualization of Segmentation results of bad predictions
------------------------
| Segmentation Ground Truths | Predicted Class | Accuracy |
|-------------|-----------------|---------------------|
|  |  | 0.5461 |
|  |  | 0.5658 |
| 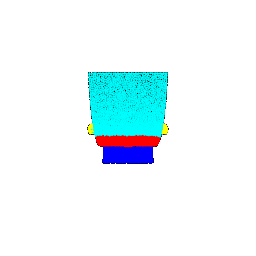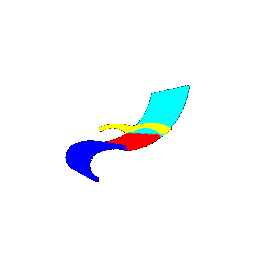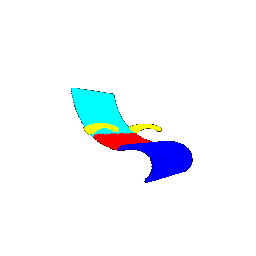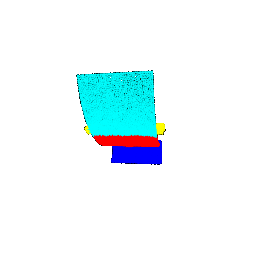 |  | 0.6118 |
Interpretation
------------------------
**Analysis:**
The segmentation model exhibits strong performance across the majority of cases, yet there are instances where it falters. Notably, challenges arise in scenarios where there are substantial overlaps between various sections of the sofa or when the parts are not distinctly separated. These complexities heighten the difficulty for the model to accurately segment and identify the boundaries, contributing to less optimal outcomes in certain cases.
Robustness Analysis
================
Experiment 1: Rotate the input point clouds by 15, 45, 90 degrees and report how much the accuracy falls
------------------------
| Rotation | Classification Test Accuracy | Segmentation Test Accuracy |
|----------|-----------------------------|-----------------------------|
| 15 | 0.8027 | 0.7356 |
| 45 | 0.3137 | 0.4771 |
| 90 | 0.4176 | 0.2395 |
| Rotation (degrees) | Point Clouds | Predicted Class | Ground Truth Class |
|--------------------|-------------|-----------------|---------------------|
| 15 |  | lamp | lamp |
| 15 |  | vase | lamp |
| 45 |  | chair | chair |
| 45 |  | lamp | chair |
| 90 |  | vase | vase |
| 90 |  | lamp | chair |
Segmentation Results :
| Rotation (degrees) | Segmentation Ground Truths | Prediction | Accuracy |
|--------------------|----------------------------|-----------------|----------|
| 15 | 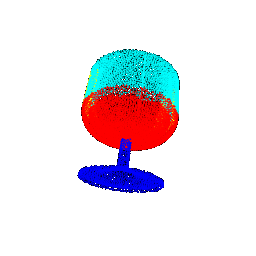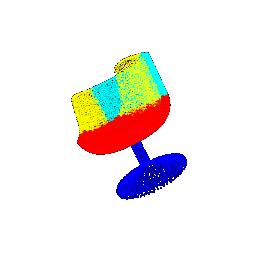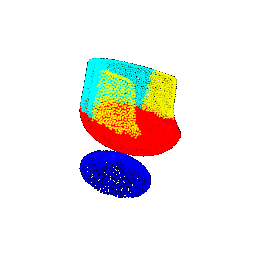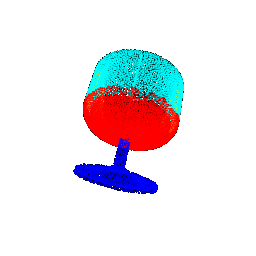 |  | 0.6645 |
| 45 | 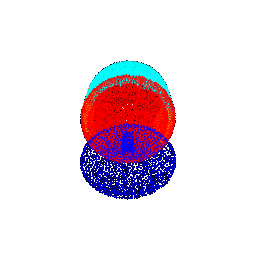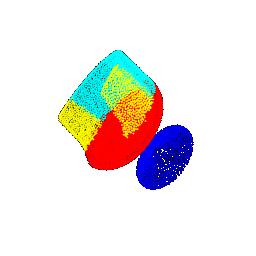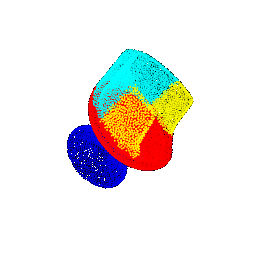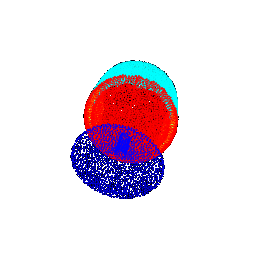 | 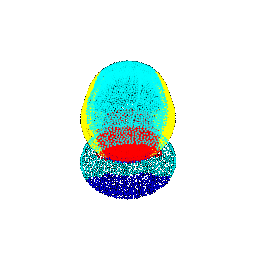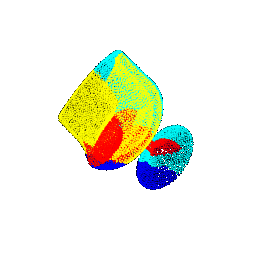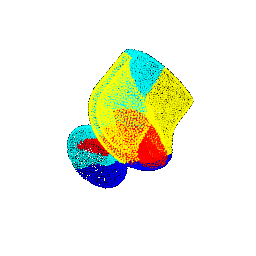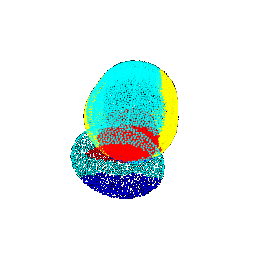 | 0.4703 |
| 90 |  | 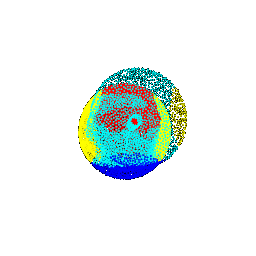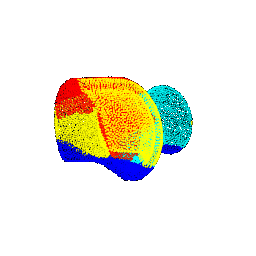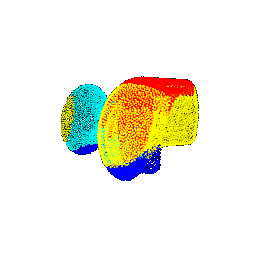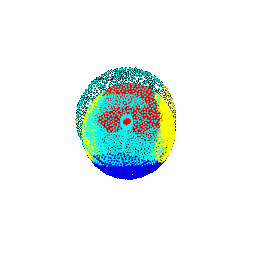 | 0.3213 |
### Interpretation
**Analysis:**
The findings indicate a decline in test accuracies for both classification and segmentation tasks as the rotation degrees decrease. Specifically, in the classification task, there is a notable reduction in the model's performance for the chair class post-rotation. This is likely attributed to the absence of rotated objects during training, resulting in the model's failure to grasp the rotation invariant property crucial for accurate rotated chair classification.
Conversely, the segmentation task experiences a significant deterioration in model performance after a 45-degree rotation. This decline may stem from the model's failure to comprehend the semantic meaning of segmented parts, focusing solely on spatial relationships. Consequently, the predictions misalign with the actual segmentation, particularly in differentiating between high and low subparts.
Experiment 2: Input a different number of points (10000, 5000, 1000, 500) points per object:
------------------------
| Number of points | Classification Test Accuracy | Segmentation Test Accuracy |
|------------------|------------------------------|----------------------------|
| 10000 | 0.9779 | 0.8884 |
| 5000 | 0.9737 | 0.8889 |
| 1000 | 0.9695 | 0.8893 |
Classification Results :
| Number of points | Point Clouds | Predicted Class | Ground Truth Class |
|--------------------|-------------|-----------------|---------------------|
| 10000 |  | lamp | lamp |
| 5000 |  | lamp | lamp |
| 1000 |  | lamp | lamp |
Segmentation Results :
| Number of points | Segmentation Ground Truths | Prediction | Accuracy |
|--------------------|----------------------------|-----------------|----------|
| 10000 |  |  | 0.9586 |
| 5000 | 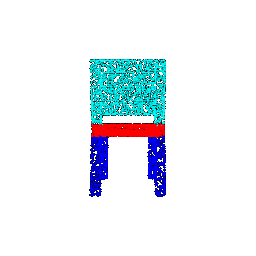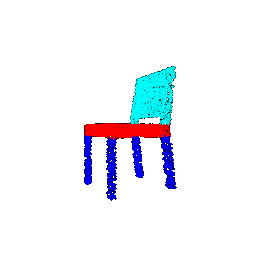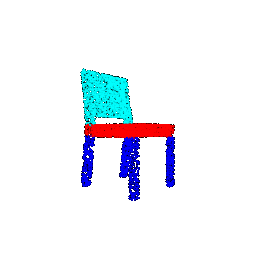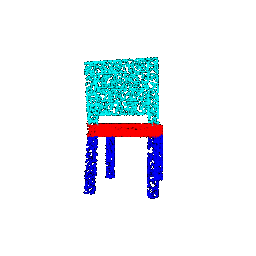 | 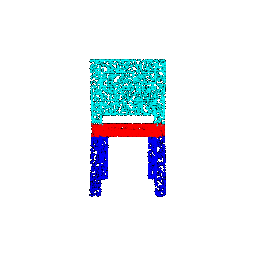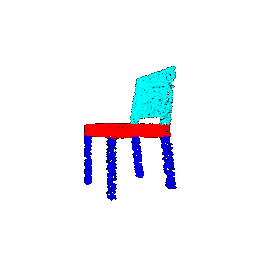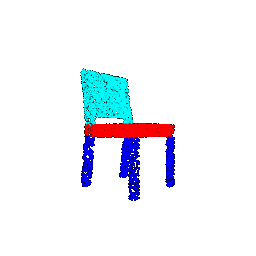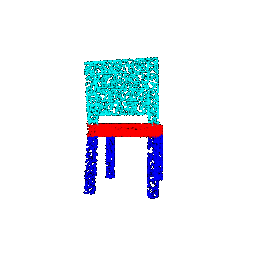 | 0.9568 |
| 1000 |  |  | 0.9570 |
### Interpretation
**Analysis:**
The outcomes reveal that both classification and segmentation models exhibit resilience to a reduction in the number of points. This resilience can be attributed to the observation that, despite a substantial decrease in point size from 10000 to 1000, the sparse points remain effective in outlining the general boundaries and surfaces of objects. This capacity of sparse points to capture essential features contributes to the continued effectiveness of the models in tasks such as classification and segmentation.
References
================
[848F-Assignment 1 Repository](https://github.com/848f-3DVision/assignment2) : Used for the README file and starter code.
[PyTorch Official Documentation](https://pytorch.org/)
[Pytorch 3D documentation](https://pytorch3d.org/)